Tar Vs Zip Vs Gz: разница и эффективность
При загрузке файлов нередко можно увидеть расширения .tar, .zip или .gz. Но знаете ли вы разницу между Tar, Zip и Gz? Почему мы их используем и что эффективнее - tar, zip или gz?

Если вы спешите или просто хотите что-то легко запомнить, вот разница между zip, tar и gz:
.tar == несжатый архивный файл
.zip == (обычно) сжатый архивный файл
.gz == файл (архивный или нет), сжатый с помощью gzip
Немного истории архивных файлов
Как и многое другое, связанное с Unix и Unix-подобными системами, история начинается давным-давно, в не очень далекой галактике под названием семидесятые. Холодным январским утром 1979 года утилита tar появилась в составе только что выпущенной Unix V7.
Утилита tar была разработана как способ эффективной записи большого количества файлов на ленту. Даже если в настоящее время ленточные накопители неизвестны подавляющему большинству индивидуальных пользователей Linux, tarballs - прозвище архивов tar - по-прежнему широко используется для упаковки нескольких файлов или даже целого дерева каталогов в один файл.
Важно помнить, что обычный tar-файл - это просто архив, данные которого не сжаты. Другими словами, если вы заархивируете 100 файлов по 50 кБ, то в итоге получите архив размером около 5000 кБ. Единственный выигрыш, на который вы можете рассчитывать, используя только tar, - это избежание потерь места файловой системой, поскольку большинство из них распределяют пространство с определенной гранулярностью (например, в моей системе файл длиной в один байт использует 4 кБ дискового пространства, 1000 таких файлов будут использовать 4 МБ, но соответствующий tar-архив "только" 1 МБ).
Стоит упомянуть, что tar, конечно, не единственный стандартный инструмент Unix для создания архивов. Программисты, вероятно, знают ar, поскольку сегодня он в основном используется для создания статических библиотек, которые представляют собой не более чем архивы скомпилированных файлов. Но ar можно использовать для создания архивов любого типа. Фактически, файлы пакетов .deb, используемые в системах Debian, являются архивами ar! А в MacOS X пакеты mpkg являются (являлись?) сжатыми gzip-архивами cpio. Тем не менее, ни ar, ни cpio не завоевали такой популярности среди пользователей, как tar. Возможно, потому, что команда tar была достаточно хороша и проста в использовании.

Создание архивов - это хорошо. Но со временем, с наступлением эры персональных компьютеров, люди поняли, что можно добиться огромной экономии на хранении данных за счет их сжатия. Так через десять лет после появления tar, в мире MS-DOS появился zip как архивный формат, поддерживающий сжатие. Наиболее распространенной схемой сжатия для zip является deflate, который сам по себе является реализацией алгоритма LZ77. Но будучи коммерчески разработанным компанией PKWARE, формат zip в течение многих лет страдал от патентного обременения.
Таким образом, параллельно был создан gzip, чтобы реализовать алгоритм LZ77 в свободной программе, не нарушая ни одного патента PKWARE.
Ключевой элемент философии Unix - "Делай одно дело и делай его хорошо", gzip был разработан только для сжатия файлов. Поэтому, чтобы создать сжатый архив, сначала нужно создать архив, например, с помощью утилиты tar. А после этого сжать этот архив. Это файл .tar.gz (иногда его сокращают до .tgz, чтобы еще раз внести путаницу - и чтобы соответствовать давно забытым ограничениям на имена файлов 8.3 MS-DOS).
По мере развития информатики были разработаны другие алгоритмы сжатия, обеспечивающие более высокую степень сжатия. Например, алгоритм Берроуза-Уиллера, реализованный в bzip2 (что привело к созданию архивов .tar.bz2). Или более поздний xz, который представляет собой реализацию алгоритма LZMA, аналогичного тому, который используется в утилите 7zip.
Возможности и ограничения
Сегодня вы можете свободно использовать любой формат архивных файлов как в Linux, так и в Windows.
Но поскольку формат zip изначально поддерживается в Windows, он особенно часто встречается в кроссплатформенных средах. Формат файлов zip можно встретить даже в неожиданных местах. Например, этот формат файлов был сохранен компанией Sun для архивов JAR, используемых для распространения скомпилированных Java-приложений. Или для файлов OpenDocument(.odf, .odp ...), используемых LibreOffice или другими офисными пакетами. Все эти форматы файлов представляют собой замаскированные zip-архивы. Если вам любопытно, не стесняйтесь распаковать один из них, чтобы посмотреть, что внутри:
sh$ unzip some-file.odt Archive:some-file.odt extracting: mimetype inflating: meta.xml inflating: settings.xml inflating: content.xm [...] inflating: styles.xml inflating: META-INF/manifest.xml
Учитывая все это, в Unix-подобном мире я бы все же отдал предпочтение типу архива tar, поскольку формат zip-файла не поддерживает надежно все метаданные файловой системы Unix. Для конкретного объяснения последнего утверждения вы должны знать, что формат ZIP-файлов определяет только небольшой набор обязательных атрибутов файла для хранения каждой записи: имя файла, дата модификации, разрешения. Помимо этих основных атрибутов, архиватор может хранить дополнительные метаданные в так называемом дополнительном поле заголовка ZIP. Но поскольку дополнительные поля определяются реализацией, даже для совместимых архиваторов нет гарантий, что они будут хранить и извлекать один и тот же набор метаданных. Давайте проверим это на примере архива:
sh$ ls -lsn data/team total 0 0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team
Central directory entry #5:
---------------------------
data/team
[...]
apparent file type: binary
Unix file attributes (100644 octal): -rw-r--r--
MS-DOS file attributes (00 hex): none
The central-directory extra field contains:
- A subfield with ID 0x5455 (universal time) and 5 data bytes.
The local extra field has UTC/GMT modification/access times.
- A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes:
01 04 e8 03 00 00 04 d0 07 00 00.Как вы видите, информация о владельце (UID/GID) является частью дополнительного поля - это может быть неочевидно, если вы не знаете шестнадцатеричной системы или того, что метаданные ZIP хранятся в формате little-endian, но для краткости "e803" - это "03e8", что равно "1000", UID файла. А "07d0" - это "d007", что равно 2000, GID файла.
В этом конкретном случае инструмент Info-ZIP zip, имеющийся в моей системе Debian, сохранил некоторые полезные метаданные в дополнительном поле. Но нет никакой гарантии, что это дополнительное поле будет записано каждым архиватором. И даже если оно присутствует, нет гарантии, что оно будет понято инструментом, используемым для извлечения архива.
Хотя мы не можем отвергать традицию как мотивацию для использования tarballs, на этом небольшом примере вы понимаете, почему все еще есть некоторые (краеугольные?) случаи, когда tar нельзя заменить zip. Это особенно верно, когда вы хотите сохранить все стандартные метаданные файла.
Тест на эффективность Tar vs Zip vs Gz
Я буду говорить здесь об эффективности использования пространства, а не времени - но, как правило, алгоритм сжатия потенциально эффективнее, чем больше процессор, который он требует.
Чтобы дать вам представление о степени сжатия, получаемой при использовании различных алгоритмов, я собрал на своем жестком диске около 100 Мб файлов популярных форматов. Вот результат, полученный на моей системе Debian Stretch (все размеры указаны в du -sh):
| file type | .jpg | .mp3 | .mp4 | .odt | .png | .txt |
| number of files | 2163 | 45 | 279 | 2990 | 2072 | 4397 |
| space on disk | 98M | 99M | 99M | 98M | 98M | 98M |
| tar | 94M | 99M | 98M | 93M | 92M | 89M |
| zip (no compression) | 92M | 99M | 98M | 91M | 91M | 86M |
| zip (deflate) | 87M | 98M | 93M | 85M | 77M | 28M |
| tar + gzip | 86M | 98M | 93M | 82M | 77M | 27M |
| tar + bz2 | 87M | 98M | 93M | 42M | 71M | 22M |
| tar + xz | 70M | 98M | 22M | 348K | 51M | 19M |
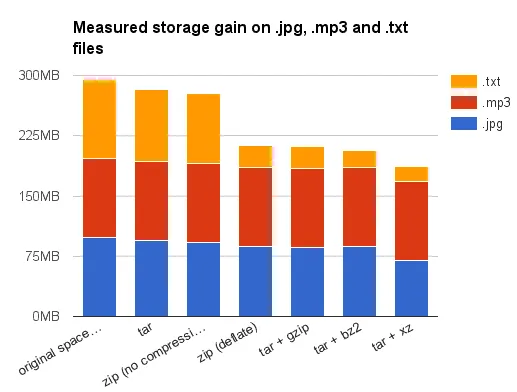
Во-первых, я призываю вас отнестись к этим результатам с большой долей соли: файлы данных на самом деле были файлами, болтающимися на моем жестком диске, и я бы ни в коем случае не утверждал, что они являются репрезентативными. Кроме того, должен признаться, что я выбрал эти типы файлов не случайно. Я уже говорил, файлы .odt - это уже zip-файлы. Поэтому скромный выигрыш, полученный при сжатии их во второй раз, неудивителен (за исключением bzip2 или xy, но я бы рассматривал это как статистическую аномалию, вызванную низкой неоднородностью моих файлов данных - содержащих несколько резервных копий или рабочих версий одних и тех же документов).
Что касается .jpg, .mp3 и .mp4: возможно, вы знаете, что это уже сжатые файлы данных. Еще лучше, если вы слышали, что они используют деструктивное сжатие. Это означает, что после сжатия JPEG вы не сможете в точности восстановить исходное изображение. И это правда. Но малоизвестно, что после фазы деструктивного сжатия как такового, данные сжимаются второй раз с помощью неразрушающего алгоритма Хаффмана с переменной длиной слова для удаления избыточности данных.
По всем этим причинам ожидалось, что сжатие изображений JPEG или файлов MP3/MP4 не приведет к высоким результатам. Обратите внимание, поскольку типичный файл содержит как сильно сжатые данные, так и некоторые несжатые метаданные, мы все еще можем получить небольшой выигрыш. Это объясняет, почему я все еще имел заметный выигрыш для изображений JPEG, поскольку у меня их было много - поэтому общий размер метаданных был не таким уж незначительным по сравнению с общим размером файла. Опять же, удивительные результаты при сжатии файлов MP4 с помощью xz, вероятно, связаны с большим сходством между различными файлами MP4, использованными во время моих тестов. Или нет?
Чтобы окончательно развеять эти сомнения, я настоятельно рекомендую вам провести собственные сравнения. И не стесняйтесь делиться с нами своими наблюдениями, используя раздел комментариев ниже!